We present PRISM (Demystifying Retention and Interaction in Mid-Training), a comprehensive empirical study of mid-training design choices for large language models. Through controlled experiments across seven open-source base models spanning four families (Granite, LLaMA, Mistral, Nemotron-H), two architecture types (dense Transformer and attention-Mamba hybrid), and scales from 3B to 24B parameters, we systematically investigate what data to use, when to apply mid-training, how it interacts with reinforcement learning (RL), and whether findings generalize across architectures.
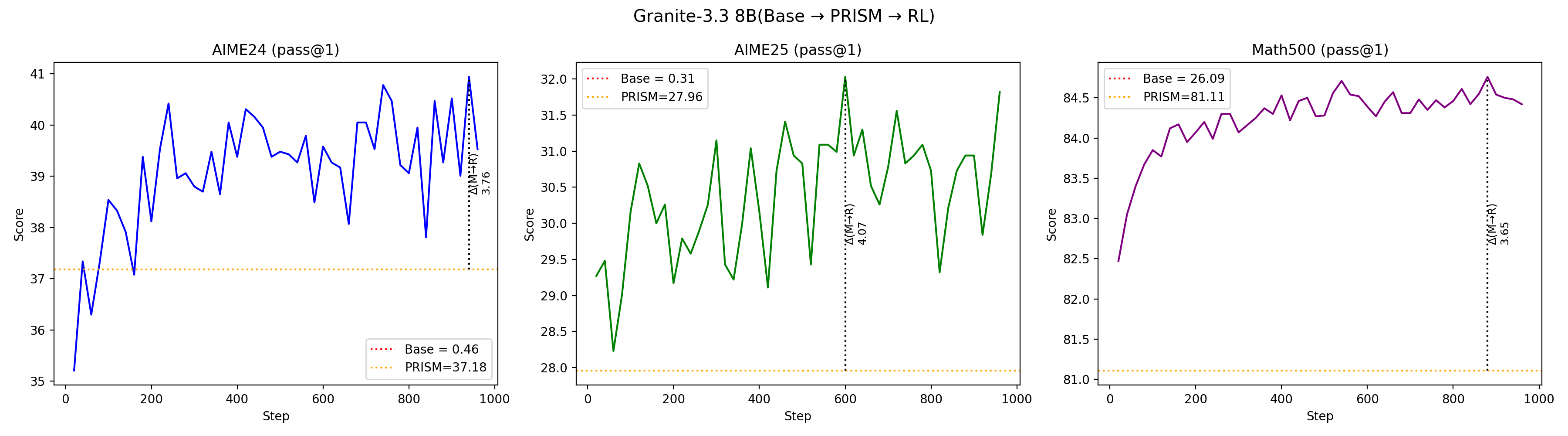
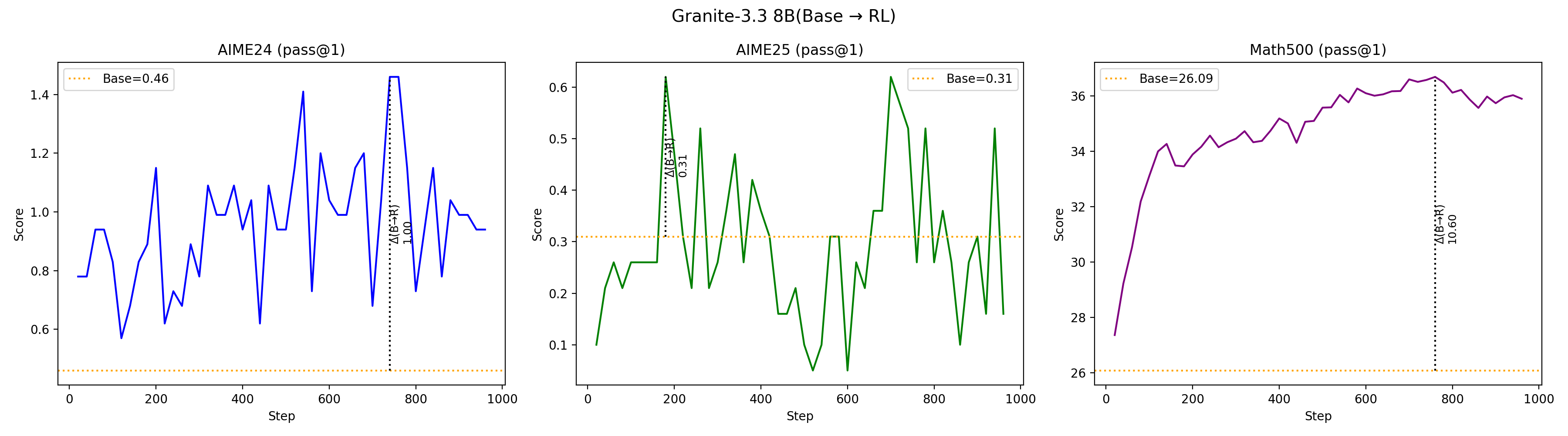
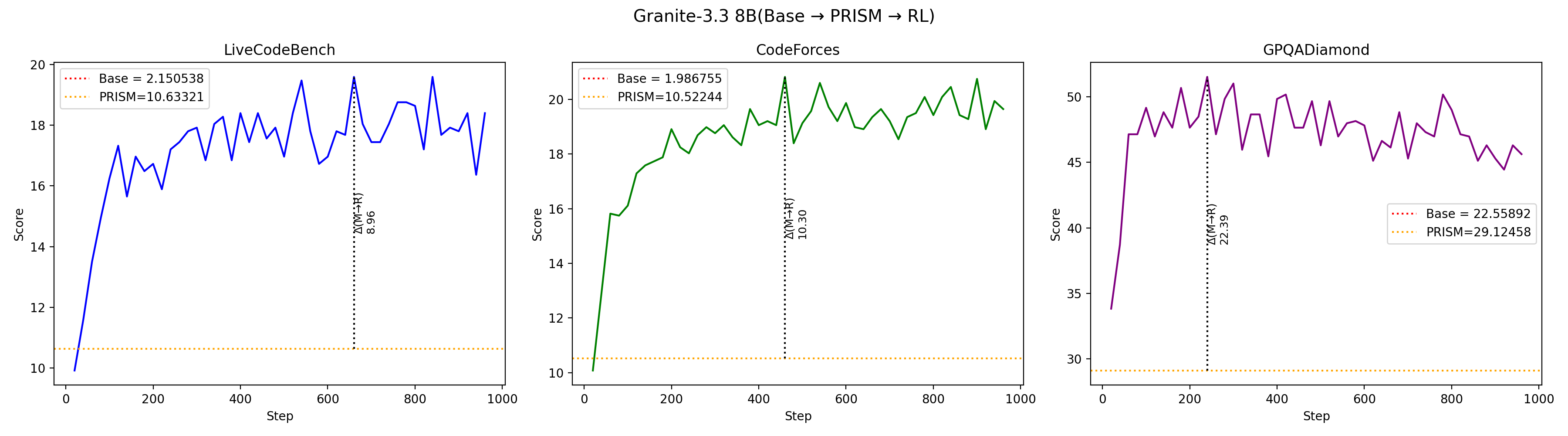
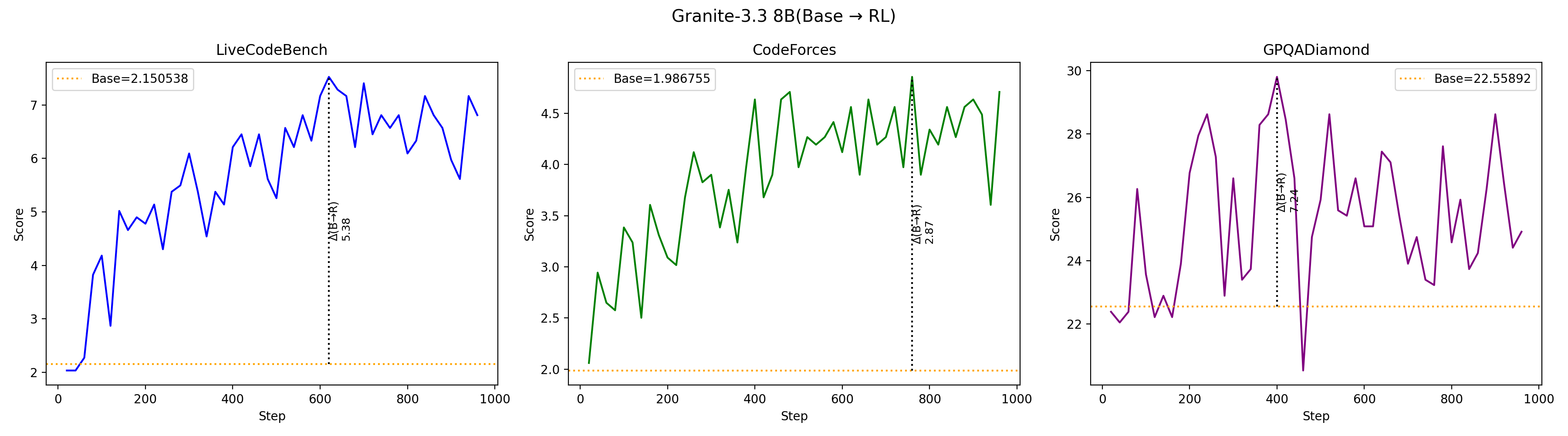
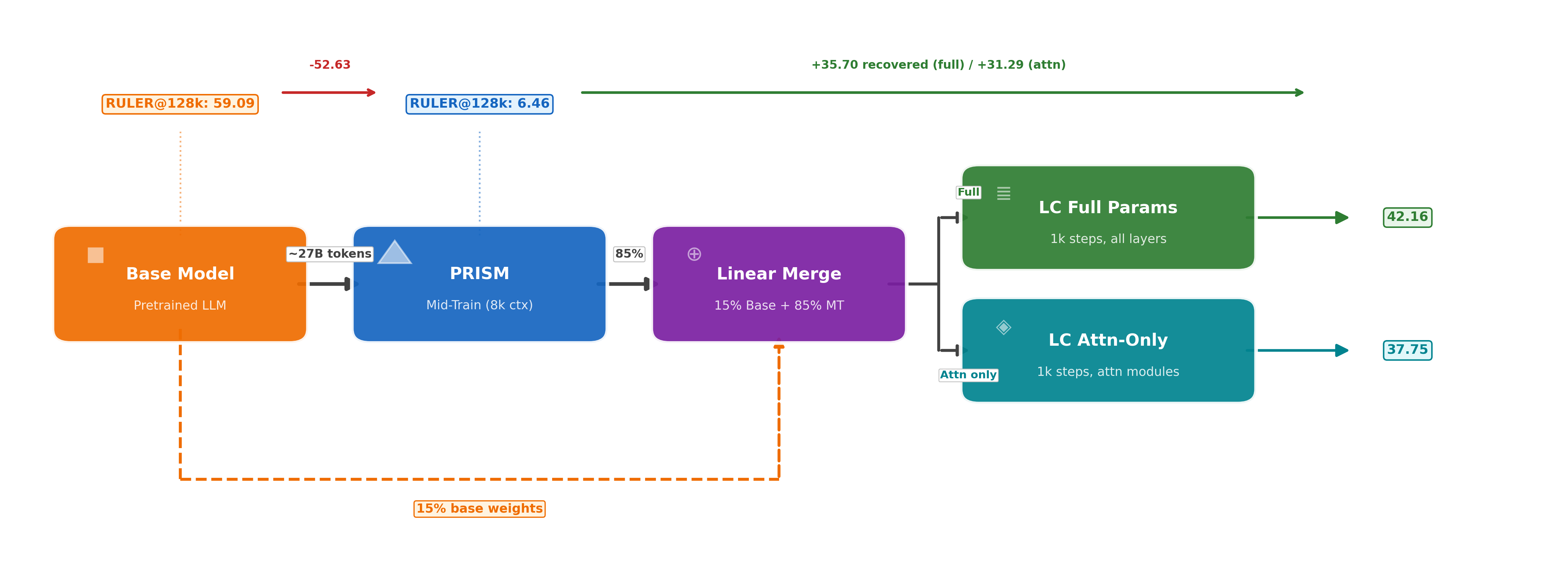
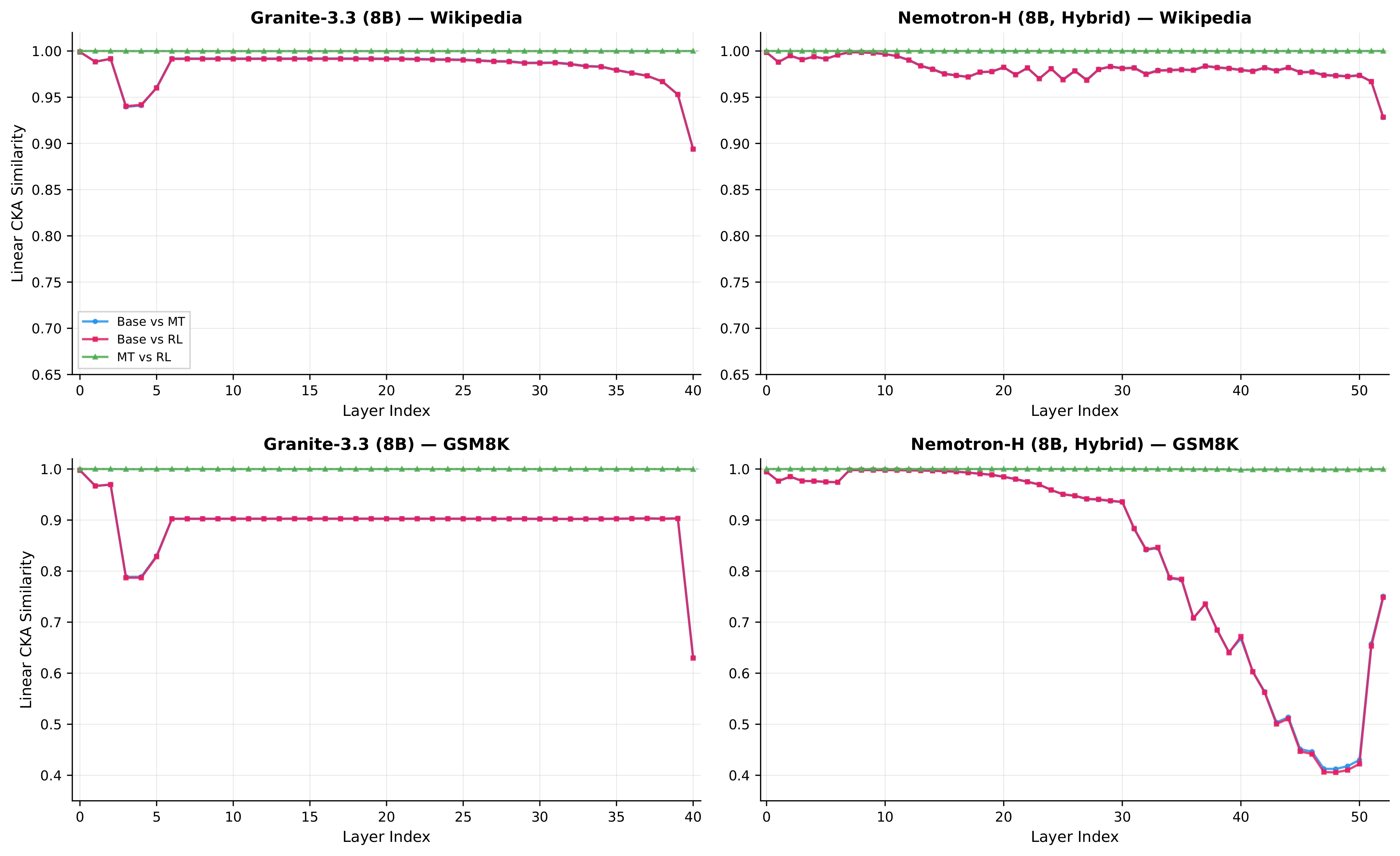
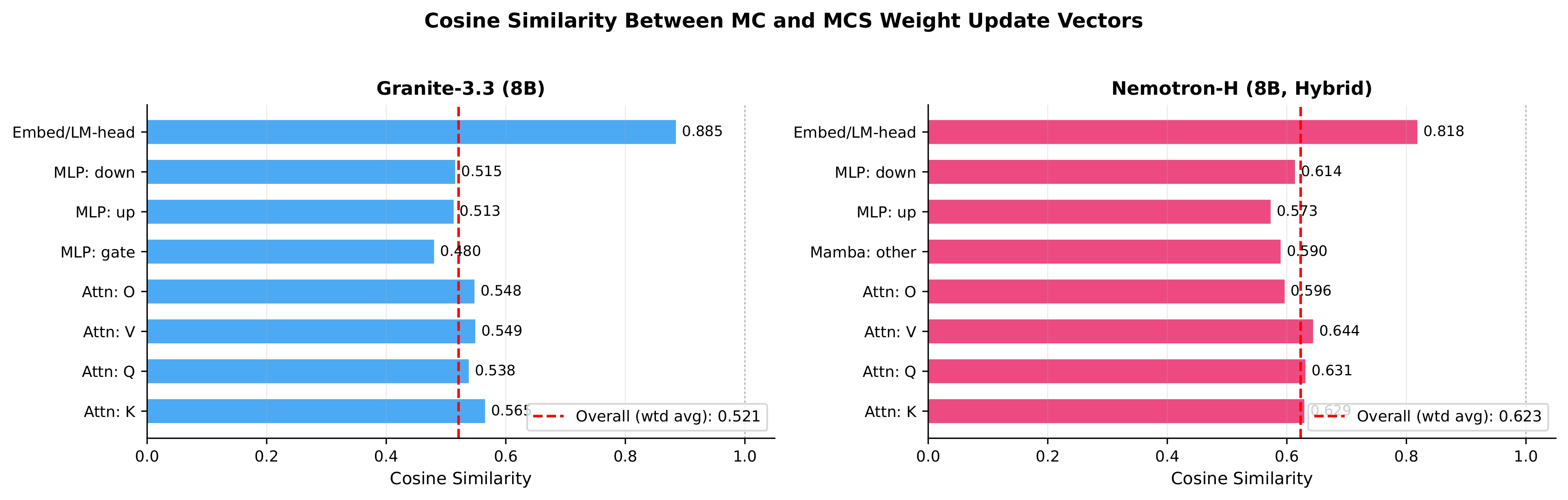
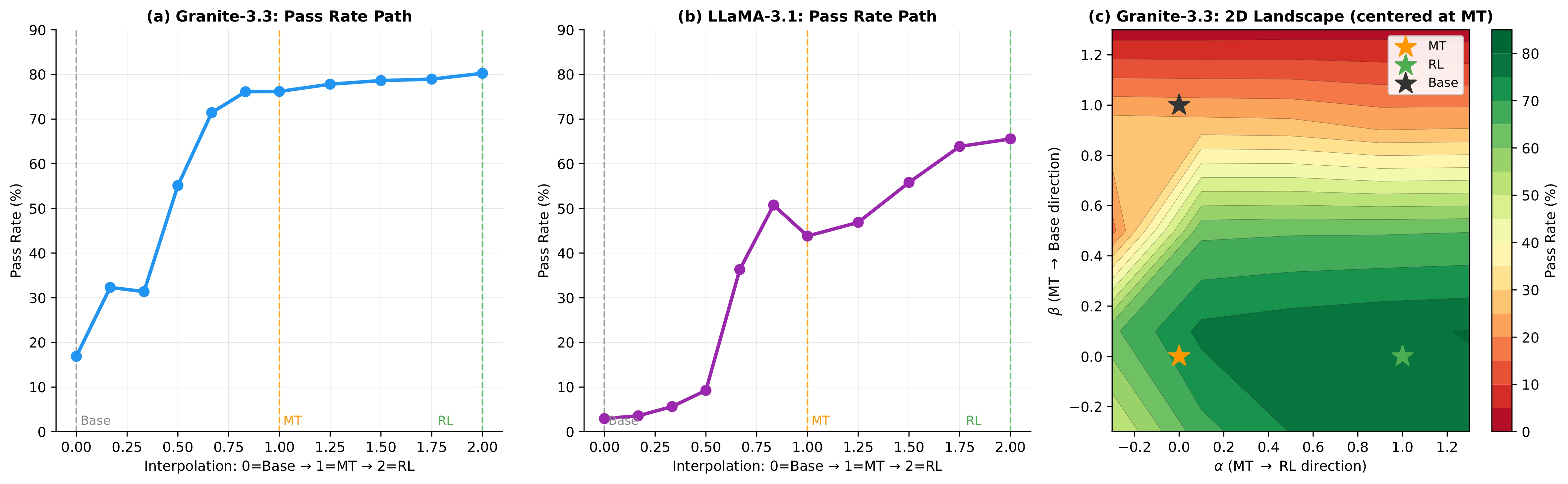
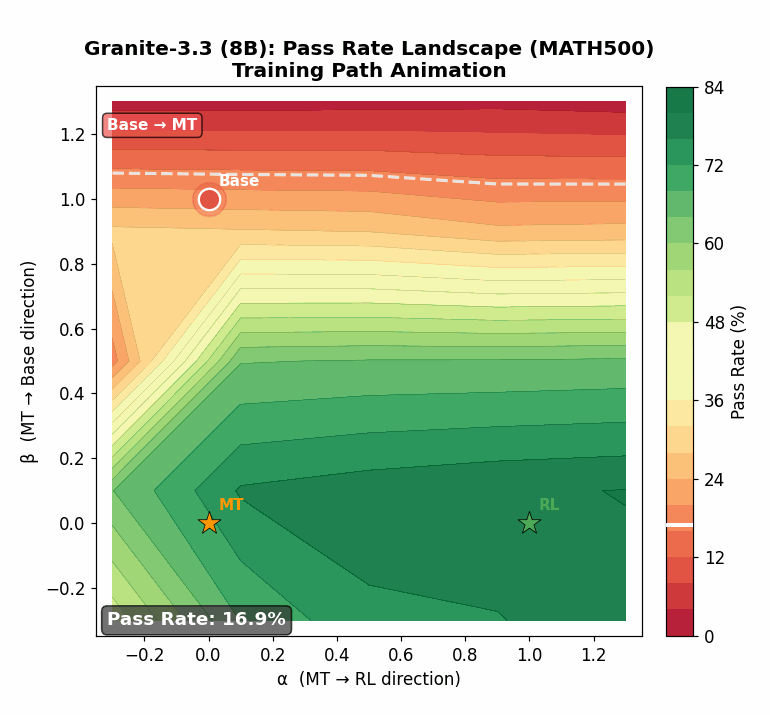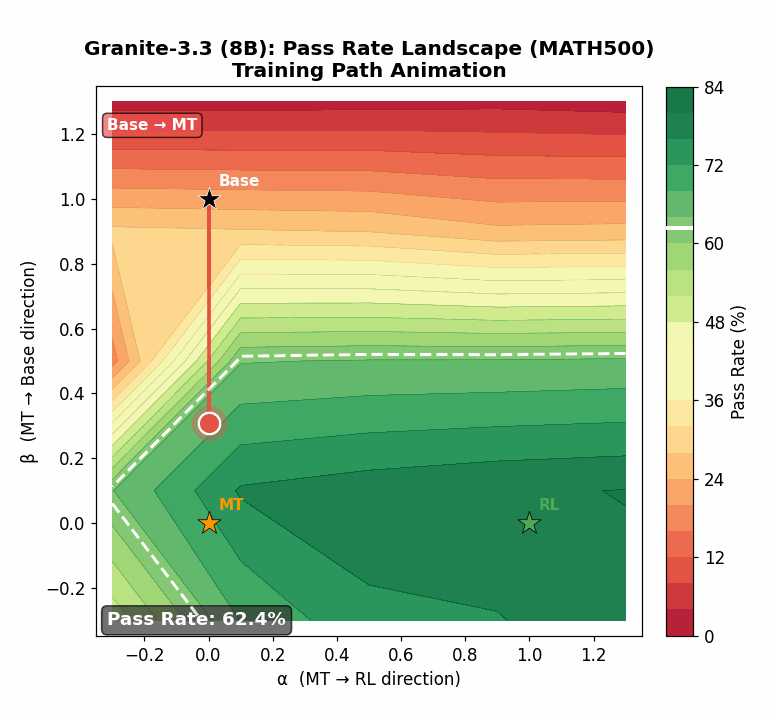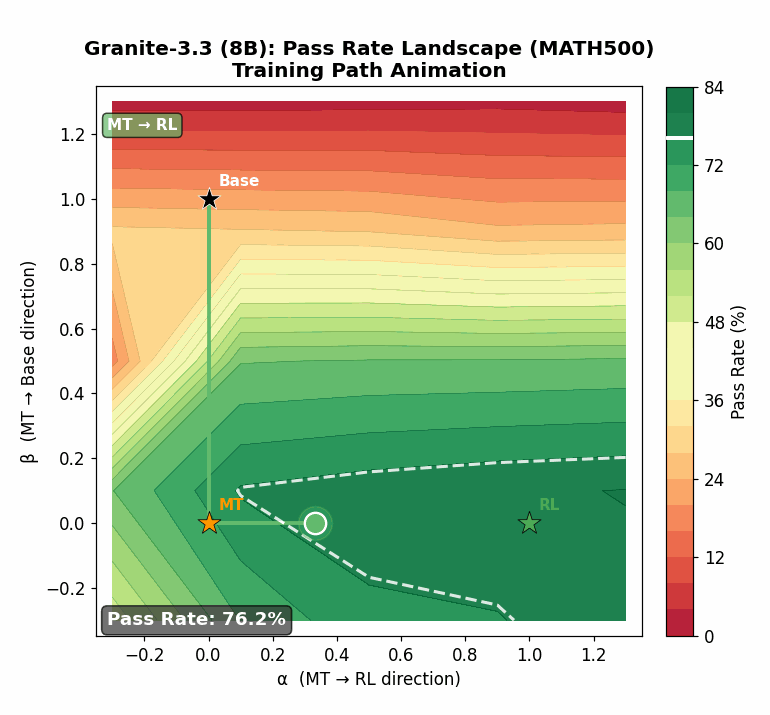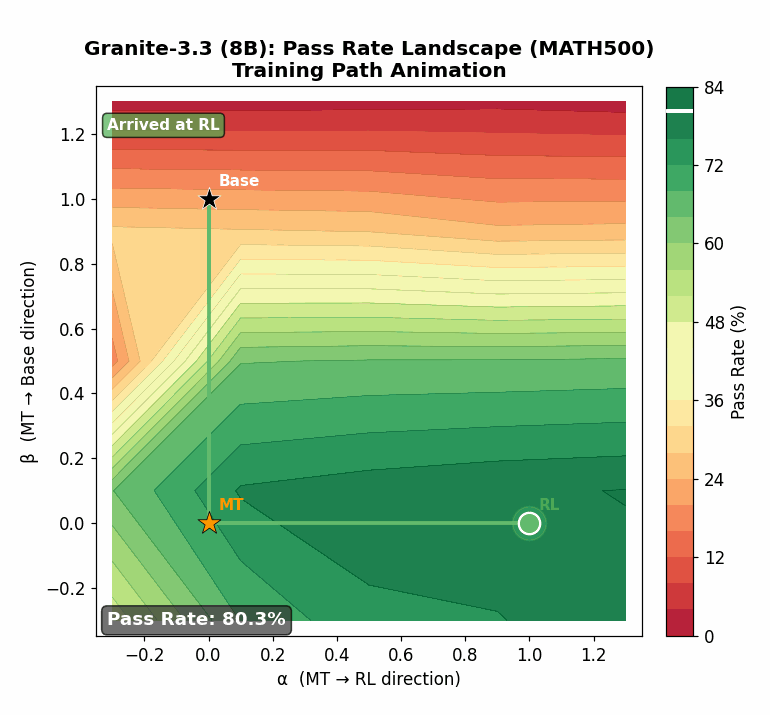
Using targeted mid-training mixtures of only ~27B high-quality tokens, PRISM yields +15 to +40 point math gains, +5 to +12 point code gains, and +6 to +13 point science gains across all tested models, while preserving general-purpose performance. Crucially, data composition choices matter most at mid-training, not at RL: including science data during mid-training unlocks +17 to +28 point GPQA-Diamond gains during RL, while changing the RL mix produces less than 2 point differences. The full PRISM-to-RL pipeline transforms base models scoring under 12 AVG into models scoring 29-42 AVG, a 3-4x improvement. Mechanistically, mid-training densely restructures >90% of weights while RL makes sparse, front-loaded refinements to ~5% of parameters. Representational geometry is largely preserved through RL (CKA >0.998 across models and input distributions), while different mid-training data mixtures produce same-magnitude but differently-directed weight updates (cosine similarity 0.52 for Granite-3.3, 0.62 for Nemotron-H). Pass rate landscape interpolation shows a generally increasing pass rate from Base (17%) to Mid-Training (76%) to RL (80%) for Granite-3.3, consistent with mid-training progressively improving the model's configuration for RL. Benefits hold for both dense Transformers and attention-Mamba hybrids, from 3B to 24B parameters.